Identificación de Regímenes de Mercado con K-Means
| *Post 1 de 3 | Serie: Regímenes de Mercado* |
Aviso al lector
Este post nace tras leer Modeling Market States with Clustering and State Machines de Oliva y Tinjala (2025). Lo aquí desarrollado parte de una lectura atenta del artículo, que recomiendo a quien haya tenido a bien acabar en esta web.
Mi objetivo no es menospreciar el trabajo de los autores, sino explorar los “¿y si…?” que surgen al leer un paper interesante. ¿Por qué K=5? ¿Qué pasa con la correlación entre features? ¿Captura realmente el modelo la estructura temporal de los retornos?
Nada de lo presente en esta web es consejo de inversión ni tiene por qué estar libre de errores.
Si quieres reproducir el análisis, el notebook completo está disponible en Google Colab (enlace pendiente).
1. Introducción: ¿Por qué identificar regímenes?
1.1 ¿Qué es un régimen de mercado?
Un régimen de mercado es un periodo extendido donde un activo muestra características homogéneas de retorno, volatilidad y comportamiento. No hablamos del estado de la economía en general, sino del comportamiento específico de un activo cotizado: un índice como el S&P 500, una acción individual, o un ETF sectorial.
Es cierto que el estado de un índice amplio como el S&P 500 contiene información sobre la economía, pero el objeto de este post no es estudiar ciclos económicos sino el comportamiento de activos en bolsa.
1.2 El enfoque clásico: Buy & Hold vs Timing
La sabiduría convencional dice: “Time in the market beats timing the market”. El enfoque Buy & Hold asume que el mercado sube a largo plazo y que intentar predecir movimientos es un juego perdedor.
Una variante más sofisticada es el All Weather Portfolio de Ray Dalio (Bridgewater). La idea es que no sabemos qué régimen vendrá, así que construimos una cartera que funcione razonablemente en todos ellos. Se diversifica entre activos que responden de forma diferente a distintos entornos: acciones para crecimiento, bonos para deflación, oro y commodities para inflación.
Este enfoque es todoterreno y defensivo. Su limitación es que trata todos los momentos por igual. Si pudiéramos anticipar el régimen, podríamos sobreponderar los activos que mejor funcionan en ese entorno específico.
Esa es la promesa de la identificación de regímenes. Veamos si K-Means puede ayudarnos.
1.3 ¿Qué es clustering?
Existen diferentes tipos de clustering que no vamos a detallar, pero la idea básica es la siguiente: son algoritmos que buscan agrupar puntos de forma que los de un mismo grupo sean similares entre sí y diferentes a los de otros grupos.
En este post usamos K-Means, uno de los algoritmos más conocidos. La mecánica es sencilla:
- Decides cuántos grupos (K) quieres.
- El algoritmo coloca K “centroides” en el espacio de características.
- Cada observación se asigna al centroide más cercano (distancia euclidiana).
- Los centroides se recalculan como el promedio de los puntos asignados.
- Se repiten los pasos 3 y 4 hasta convergencia.
Aplicado a nuestro problema: cada día de mercado tiene un vector de características derivadas del precio (momentum, volatilidad). K-Means agrupa los días con características similares. Si elegimos K=5, obtenemos 5 clusters que podemos interpretar como regímenes: “crisis”, “bull”, “contracción”, etc.—aunque los nombres se los ponemos nosotros después de analizar cada centroide.
2. Datos y Features
2.1 Los datos
Trabajamos con el SPY (ETF que replica el S&P 500):
- Periodo: 2007-01-01 a 2025-02-04
- Train: 2007-2021 (ajuste del modelo)
- Test: 2022-2025 (validación out-of-sample)
- Variable: Log-returns diarios
¿Por qué log-returns? Porque son aditivos en el tiempo y más estables estadísticamente que los retornos simples.
2.2 Features de Oliva-Tinjala
Los autores proponen 12 características basadas en dos conceptos:
Momentum — retorno acumulado en ventana de t días: \(\text{Mom}_t = \sum_{i=1}^{t} r_i\)
Volatilidad — desviación estándar en ventana de t días: \(\text{Vol}_t = \sqrt{\frac{1}{t} \sum_{i=1}^{t} (r_i - \bar{r})^2}\)
Ventanas utilizadas: 5, 10, 20, 30, 40 y 50 días.
Esto nos da 6 features de momentum + 6 de volatilidad = 12 features por día.
1
2
3
4
5
6
7
def compute_oliva_tinjala_features(df, window_sizes=[5, 10, 20, 30, 40, 50]):
"""Calcula features de momentum y volatilidad."""
features = pd.DataFrame(index=df.index)
for w in window_sizes:
features[f'momentum_{w}d'] = df['returns'].rolling(w).sum()
features[f'volatility_{w}d'] = df['returns'].rolling(w).std()
return features.dropna()
2.3 Observación sobre la correlación entre features
Antes de entrenar el modelo, examinamos la correlación entre features:

Observación importante:
- Correlación media Spearman entre features de volatilidad: ~0.82
- Correlación media Spearman entre features de momentum: ~0.54
Una correlación de 0.82 significa que las 6 ventanas de volatilidad aportan información casi idéntica. Este patrón es esperable: la volatilidad de 20 días incluye los mismos datos que la de 10 días, solo con contexto adicional.
Por ahora, mantenemos las 12 features del paper original para garantizar comparabilidad. En la sección de Limitaciones analizaremos las implicaciones de esta redundancia.
3. Entrenamiento del Modelo
3.1 Estandarización
K-Means usa distancia euclidiana, lo que significa que features con mayor escala dominarían el cálculo. Para evitarlo, estandarizamos:
1
2
3
4
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
Cada feature queda con media 0 y desviación estándar 1.
3.2 K-Means con K=5
¿Por qué K=5? Seguimos el paper de Oliva-Tinjala para garantizar comparabilidad. Existen métodos para elegir K (BIC, Silhouette, método del codo), pero el BIC en K-Means decrece monótonamente con K—no hay un “óptimo” claro como en GMM.
1
2
3
4
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=5, random_state=42, n_init=200)
labels = kmeans.fit_predict(features_scaled)
3.3 Nomenclatura de regímenes
Los clusters no vienen con nombres. Tras analizar las características de cada centroide (media, volatilidad, Sharpe), asignamos etiquetas interpretables:
| Cluster | Nombre | Característica dominante |
|---|---|---|
| 0 | Recuperación | Rebote tras crisis, Sharpe +3.35 |
| 1 | Aplanamiento | Mercado lateral, baja volatilidad, domina el 58.7% del tiempo |
| 2 | Crisis | Volatilidad extrema, retornos muy negativos |
| 3 | Expansión | Momentum positivo sostenido, Sharpe +5.61 |
| 4 | Contracción | Retornos negativos moderados |
4. Interpretación Económica de los Regímenes
4.1 Estadísticas por régimen
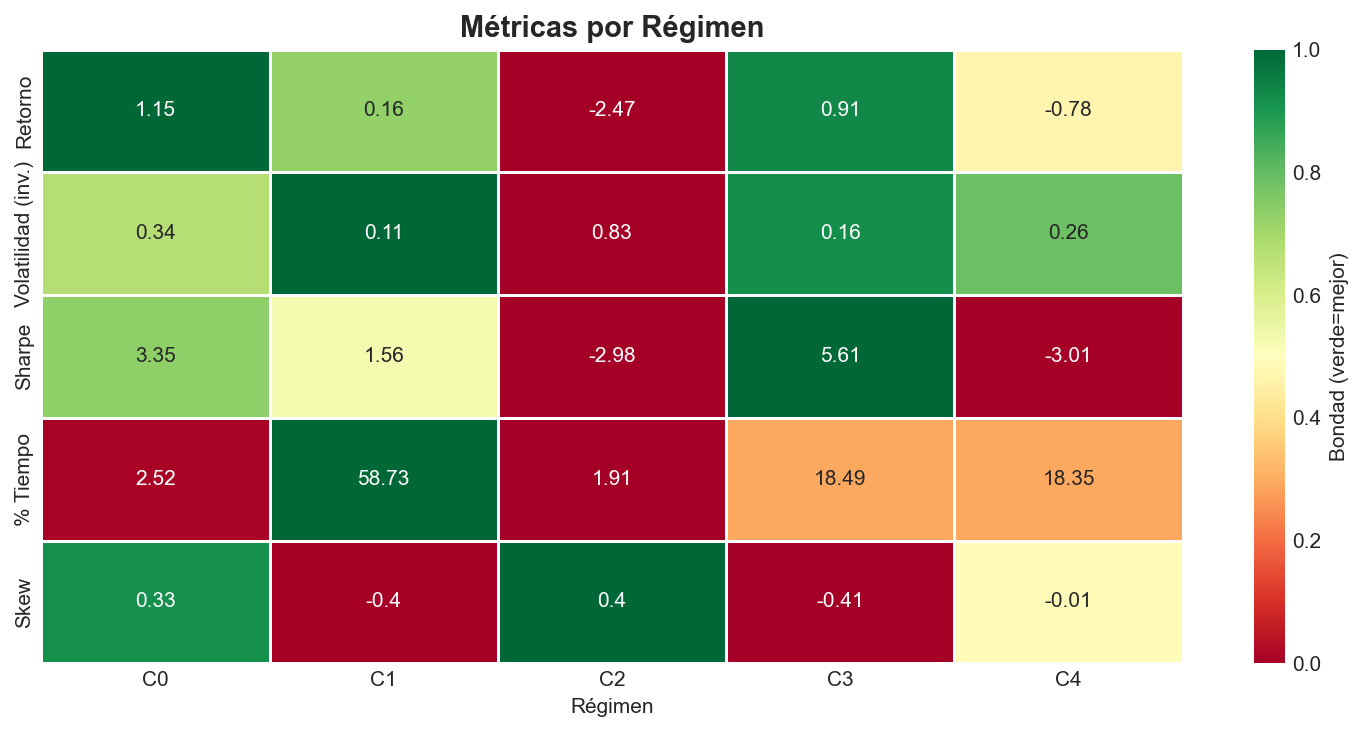
| Régimen | Media anual. | Vol. anual. | Sharpe | Skewness | % tiempo |
|---|---|---|---|---|---|
| Recuperación | +115% | 34% | +3.35 | +0.33 | 2.5% |
| Aplanamiento | +16% | 11% | +1.56 | -0.40 | 58.7% |
| Crisis | -247% | 83% | -2.98 | +0.40 | 1.9% |
| Expansión | +91% | 16% | +5.61 | -0.41 | 18.5% |
| Contracción | -78% | 26% | -3.01 | -0.01 | 18.4% |
4.2 Observaciones clave
Crisis: Retorno anualizado de -247%, volatilidad del 83%, pero ocupa solo el 1.9% del tiempo. El skewness positivo (+0.40) indica que dentro de las crisis hay rebotes violentos—los famosos “dead cat bounces”.
Aplanamiento: Domina el 58.7% del tiempo. Sharpe de +1.56, volatilidad controlada (11%). Skewness negativo (-0.40) refleja la asimetría típica del mercado: subidas graduales con caídas ocasionales bruscas. Es el régimen “base” del mercado.
Recuperación: Solo el 2.5% del tiempo, pero con un retorno alto (+115% anualizado) y Sharpe de +3.35. Es el rebote posterior a una crisis—breve pero intenso.
Expansión: El mejor Sharpe (+5.61) con volatilidad moderada (16%). Representa el mercado alcista con momentum sostenido.
La estructura de Sharpe es coherente: positivo en regímenes alcistas (Expansión, Recuperación, Aplanamiento), negativo en bajistas (Crisis, Contracción).
5. Persistencia y Transiciones
5.1 Visualización temporal
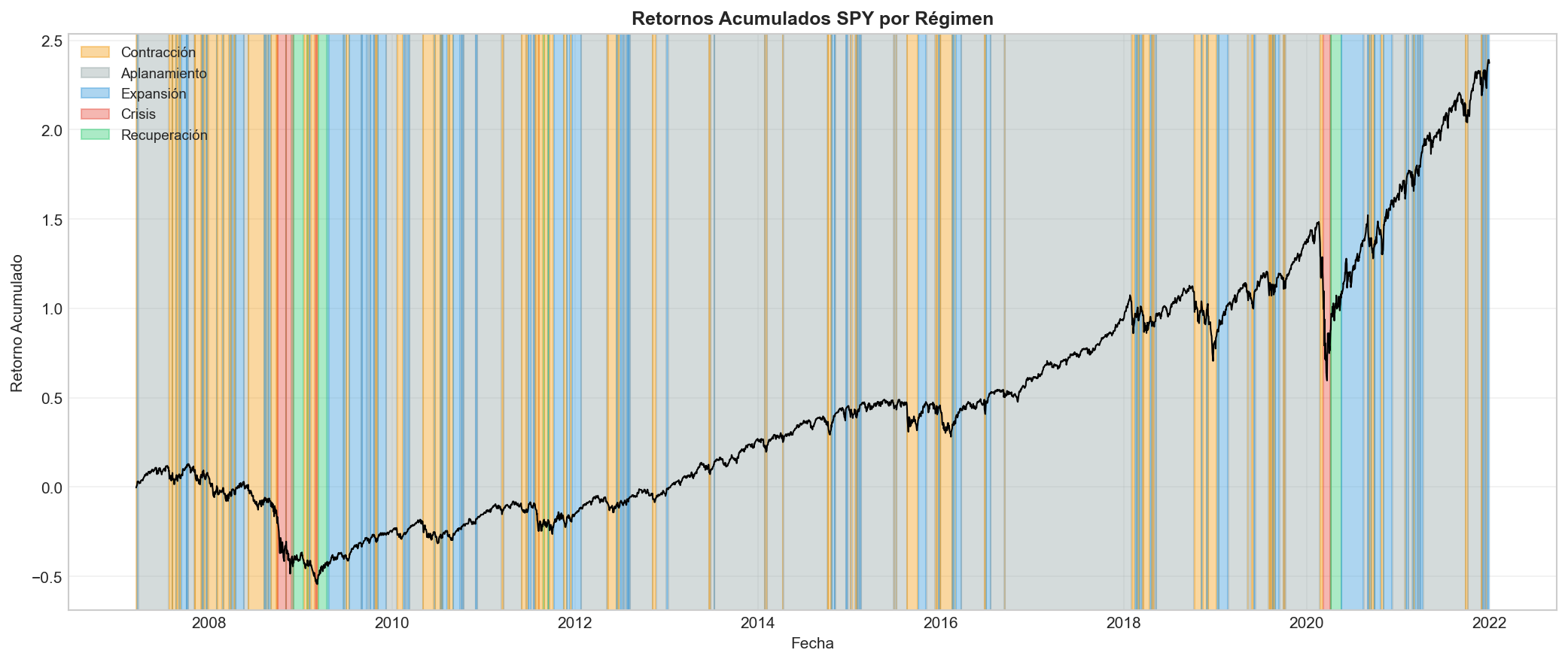
El gráfico muestra el SPY con el fondo coloreado según el régimen identificado. Se aprecian claramente:
- Crisis financiera 2008: Cluster rojo (Crisis) dominante
- COVID marzo 2020: Transición rápida Crisis → Recuperación
- Bear market 2022: Predominio de Contracción
5.2 Duración de los regímenes
| Régimen | Media (días) | Mediana | Máximo | Nº rachas |
|---|---|---|---|---|
| Recuperación | 9.4 | 3 | 28 | 10 |
| Aplanamiento | 25.2 | 4 | 350 | 87 |
| Crisis | 7.9 | 4 | 23 | 9 |
| Expansión | 7.3 | 4 | 62 | 94 |
| Contracción | 6.5 | 3 | 44 | 105 |
Observación: Los regímenes son persistentes—no cambian cada día. Aplanamiento tiene la mayor duración media (25 días) con una racha máxima de 350 días consecutivos.
5.3 Matriz de transición
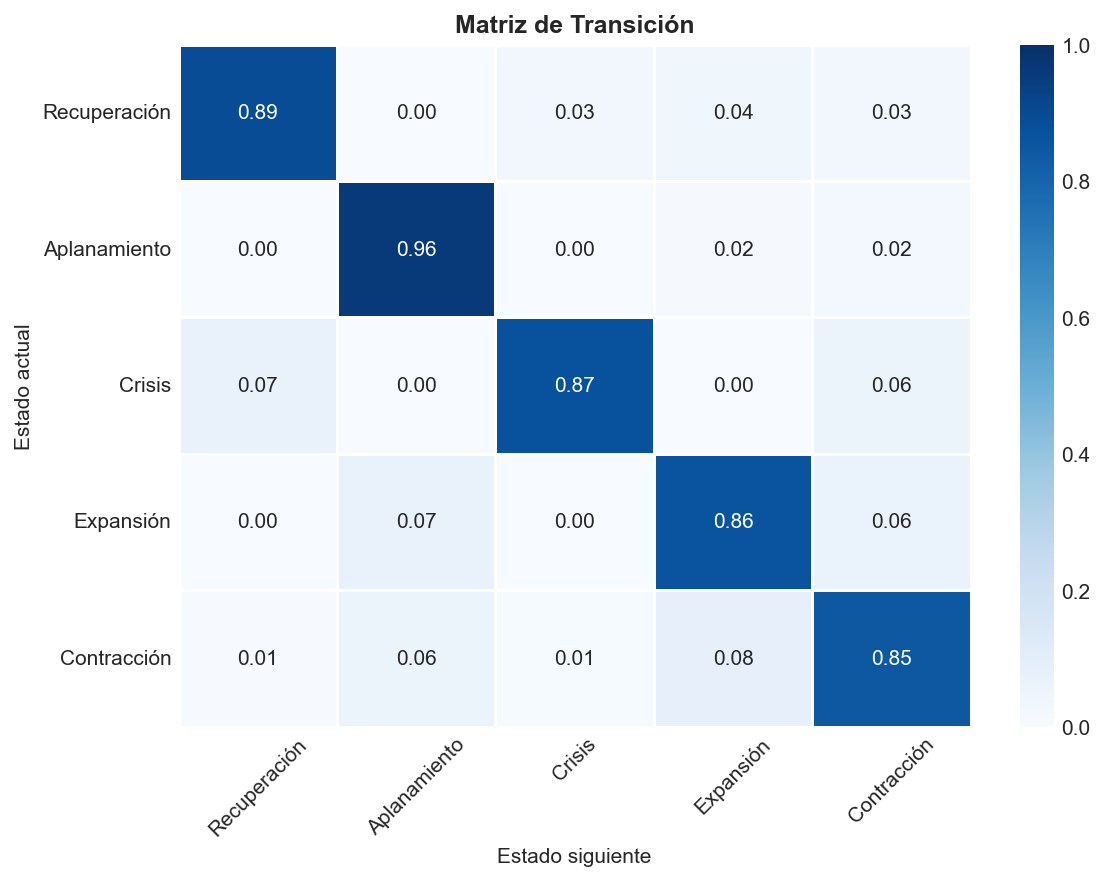
La matriz muestra la probabilidad de pasar de un régimen a otro al día siguiente.
Observaciones:
- Diagonal dominante: La probabilidad de permanecer en el mismo régimen es la más alta (>84% en todos los casos). Aplanamiento tiene la mayor persistencia (96%).
- Crisis → Recuperación o Contracción: Cuando salimos de Crisis, las opciones son Recuperación (7%) o Contracción (5.6%).
- Contracción → Expansión: Hay un camino de 8.3% directo de Contracción a Expansión, reflejando rebotes de mercado.
5.4 Probabilidades soft: el caso de marzo 2020
K-Means asigna cada día a un único cluster, pero en las fronteras la decisión es incierta. Podemos calcular probabilidades “soft” basadas en la distancia inversa a cada centroide:
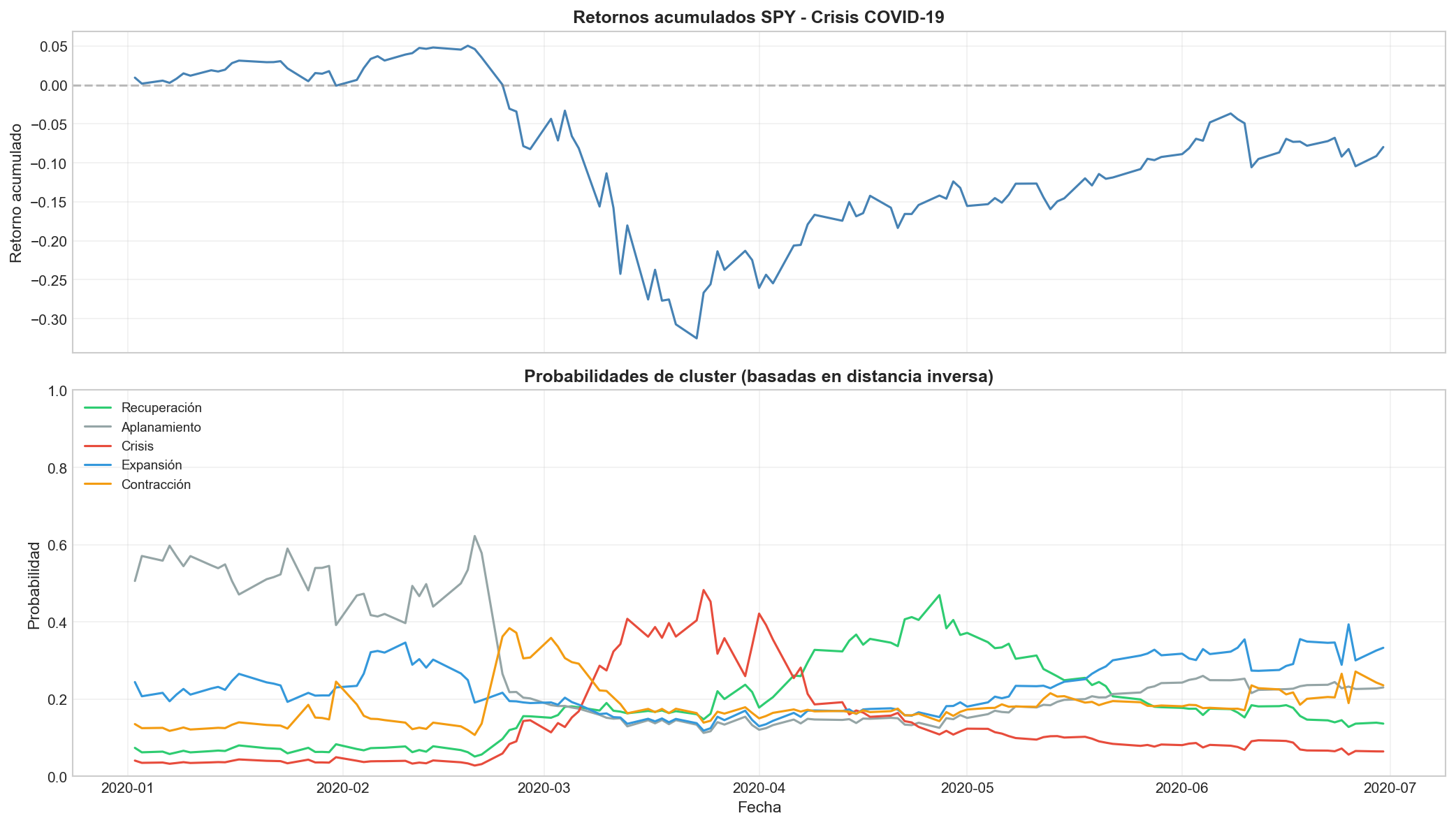
La transición de Contracción → Crisis → Recuperación se ve claramente en las probabilidades. Los picos de incertidumbre (probabilidades repartidas) ocurren en los días de transición entre regímenes.
6. ¿Captura el Modelo la Distribución Real?
6.1 El engaño de los tests estadísticos
Una forma de validar el modelo es generar retornos sintéticos y compararlos con los reales. Si el modelo captura correctamente la distribución, los sintéticos deberían ser estadísticamente indistinguibles.
Generamos retornos de una mixture i.i.d.: en cada paso, elegimos un régimen según su frecuencia histórica y muestreamos de su distribución normal.
1
2
3
4
# Simplificado
for t in range(T):
regime = np.random.choice(K, p=frequencies)
return_t = np.random.normal(mu[regime], sigma[regime])
Resultado del test Kolmogorov-Smirnov:
- Mixture vs Real: stat=0.060, p=0.00
Sorpresa: ¡El modelo no pasa el test KS! La mixture captura la distribución de forma aproximada, pero no es perfecta.
6.2 La revelación: retornos barajeados
¿Qué pasa si simplemente barajeamos los retornos reales (destruyendo toda estructura temporal)?
1
2
returns_shuffled = real_returns.copy()
np.random.shuffle(returns_shuffled)
Test KS de retornos barajeados vs reales:
- KS statistic: 0.000
- p-valor: 1.00
Los retornos barajeados pasan perfectamente el test. Obviamente: tienen exactamente la misma distribución marginal.
Conclusión: El test KS solo verifica la distribución marginal, no la estructura temporal. Los datos barajeados son “perfectos” según KS, pero han perdido toda la información temporal.
6.3 Volatility Clustering: lo que falta
| Los retornos financieros exhiben volatility clustering: periodos de alta volatilidad tienden a seguir a otros periodos de alta volatilidad. Esto se mide con la autocorrelación de | r | o r². |
| Serie | ACF(|r|, lag=1) |
|---|---|
| SPY Real | 0.3452 |
| State Machine i.i.d. | 0.0017 |
| Barajeados | -0.0023 |
Solo los datos reales muestran autocorrelación significativa (muy por encima del intervalo de confianza del 95% que es ~0.032).
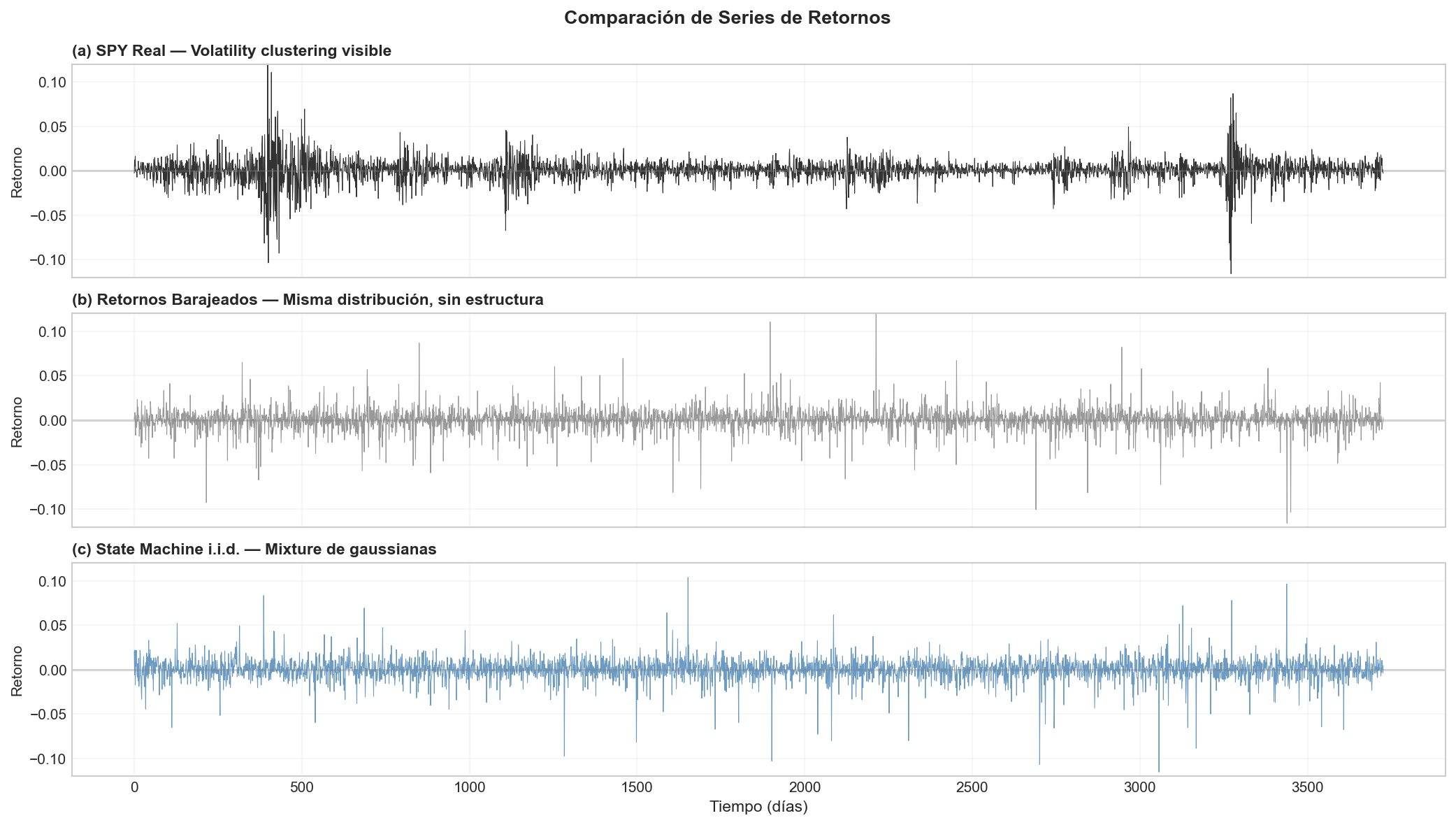
El gráfico de volatilidad rolling muestra “rachas” en los datos reales que no aparecen en la mixture ni en los barajeados.
6.4 La solución: Cadena de Markov
El problema es que la mixture i.i.d. elige el régimen de cada día de forma independiente. En la realidad, si hoy estamos en Crisis, mañana probablemente seguiremos en Crisis (matriz de transición con diagonal dominante).
Generamos retornos usando la matriz de transición estimada:
1
2
3
4
state = initial_state
for t in range(T):
returns[t] = np.random.normal(mu[state], sigma[state])
state = np.random.choice(K, p=transition_matrix[state]) # Markov!
Resultado:
- ACF(|r|, lag=1) con transiciones: 0.3337
- Captura el 96.7% del volatility clustering real
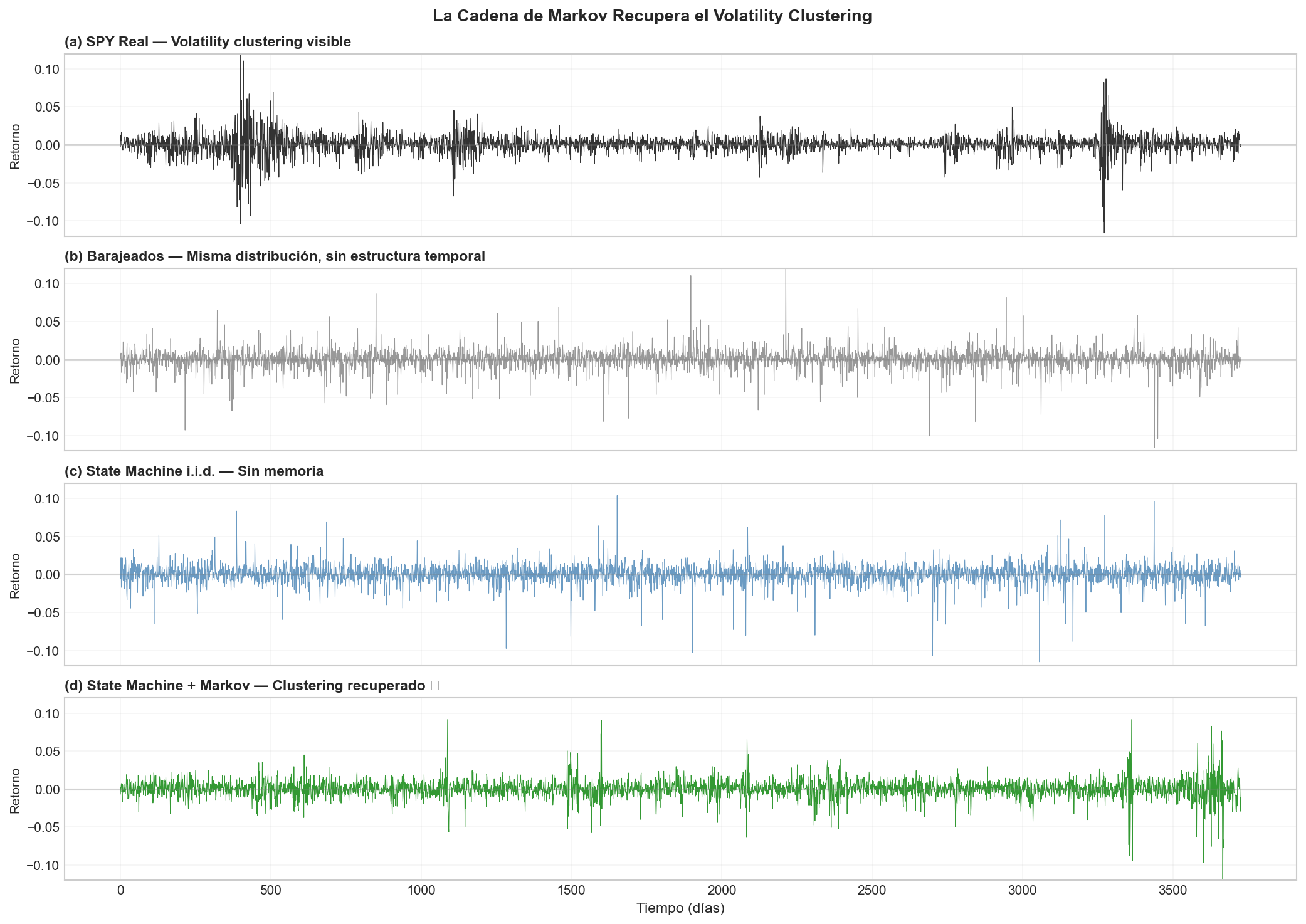
Ahora sí vemos las “rachas” de volatilidad en los datos sintéticos.
Nota técnica: Esta combinación de mixture de normales + cadena de Markov es lo que McNeil, Frey & Embrechts (Quantitative Risk Management, Sec. 6.2) llaman una “normal mixture distribution” con dependencia temporal. Es la forma canónica de capturar volatility clustering sin recurrir a modelos GARCH.
7. Validación Out-of-Sample (2022-2025)
7.1 El test real
El modelo fue entrenado con datos de 2007-2021. ¿Funciona en datos que nunca ha visto (2022-2025)?
Aplicamos el modelo entrenado a las features del periodo de test:
1
2
3
features_test = compute_features(df_test)
features_test_scaled = scaler.transform(features_test) # mismo scaler
labels_test = kmeans.predict(features_test_scaled) # mismo modelo
7.2 Comparación In-Sample vs Out-of-Sample
| Régimen | Media IS | Media OOS | Vol IS | Vol OOS |
|---|---|---|---|---|
| Recuperación | +115% | +317% | 34% | 39% |
| Aplanamiento | +16% | +17% | 11% | 11% |
| Crisis | -247% | -1129% | 83% | n/a* |
| Expansión | +91% | +102% | 16% | 17% |
| Contracción | -78% | -107% | 26% | 25% |
*Crisis OOS tiene solo 1 día, volatilidad no calculable.
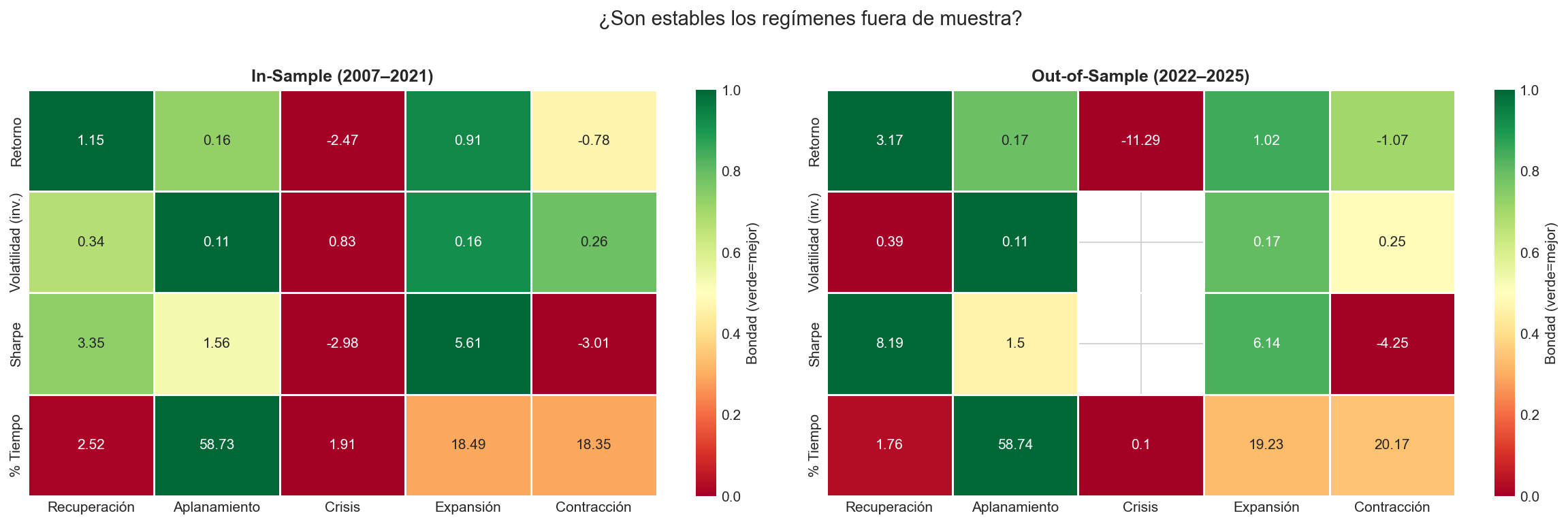
7.3 Interpretación
Lo que funciona:
- Aplanamiento, Expansión y Contracción mantienen características muy similares OOS
- Los signos del Sharpe se preservan en todos los regímenes
- Las frecuencias se mantienen estables: Aplanamiento sigue dominando (~59% del tiempo tanto IS como OOS)
Lo que cambia:
- Crisis OOS: Solo 1 día clasificado como Crisis (no hubo un crash comparable a 2008 o marzo 2020)
- Recuperación OOS: Sharpe más alto (+8.19 vs +3.35), posiblemente por los rebotes de 2023-2024
Conclusión: El modelo generaliza razonablemente, pero su utilidad para Crisis depende de tener eventos extremos en el periodo de test.
8. Limitaciones de K-Means
8.1 Clusters esféricos
K-Means asume que los clusters son “bolas”—equidistantes del centroide en todas direcciones. Pero los datos financieros rara vez cumplen esto.
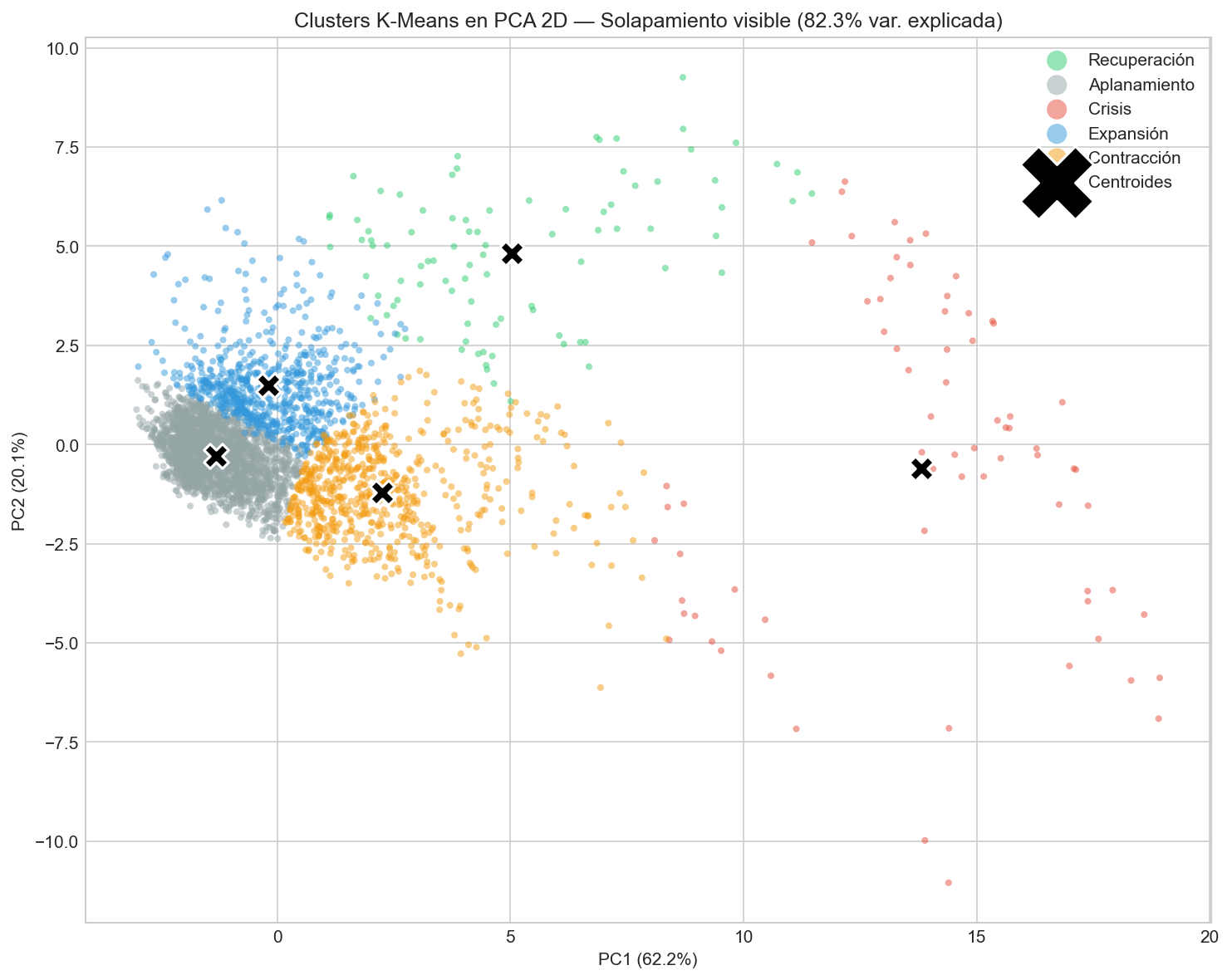
El gráfico PCA muestra que:
- Crisis y Recuperación son claramente alargados (elípticos), no esféricos
- Hay solapamiento significativo entre Aplanamiento, Expansión y Contracción
Alternativa: Gaussian Mixture Models (GMM) con covarianza completa pueden modelar clusters elípticos.
8.2 Redundancia en features
Recordemos la correlación de 0.82 entre features de volatilidad. Esto significa:
- Las 6 ventanas de volatilidad aportan información casi idéntica
- K-Means da peso implícito 6× a volatilidad vs si usáramos una sola
- La “dimensionalidad efectiva” es ~2-3, no 12
Soluciones posibles:
- Aplicar PCA antes del clustering
- Seleccionar una sola ventana por tipo (ej: momentum_20d + volatility_20d)
- Diseñar features más ortogonales (ej: ratio vol_corta/vol_larga)
8.3 Sin memoria temporal nativa
K-Means trata cada día como independiente. La matriz de transición es un “parche” post-hoc que añadimos después del clustering.
Alternativa: Hidden Markov Models (HMM) incorporan la dependencia temporal directamente en la estimación. El régimen de hoy influye en el de mañana durante el entrenamiento, no solo después.
8.4 Hacia dónde seguir
En los próximos posts exploraremos:
- Post 2: GMM con covarianza completa, HMM, features ortogonales
- Post 3: Usar los regímenes para una estrategia de inversión y medir el Sharpe resultante
9. Conclusiones
-
K-Means + features de Oliva-Tinjala identifican regímenes económicamente interpretables: Crisis con volatilidad extrema, Expansión con Sharpe alto, Aplanamiento como régimen base, etc.
-
La mixture i.i.d. captura la distribución marginal pero NO la estructura temporal: El test KS es insuficiente; necesitamos verificar el volatility clustering.
-
La matriz de transición recupera el ~96% del volatility clustering: Añadir memoria temporal (Markov) es esencial para un modelo realista.
-
El modelo generaliza razonablemente OOS: Las características de cada régimen se mantienen, aunque Crisis depende de tener eventos extremos en el test.
-
Limitaciones conocidas: Clusters esféricos, features redundantes, sin memoria temporal nativa. Son puntos de partida para mejoras.
El modelo es una herramienta de análisis, no un sistema de trading listo para usar. Entender sus supuestos y limitaciones es tan importante como saber implementarlo.
| *Notebook completo disponible en Google Colab | GitHub* |
Siguiente post: Extensiones del modelo — GMM, HMM y features ortogonales